每月省 20 刀还不是重点——我把 AI 彻底搬回了自己电脑
用 Hermes Agent + Ollama + Gemma4 搭建完全本地的飞书 AI 助手,零成本、数据不出本机。一个周末的折腾换来完整的数据主权。
上周我突然意识到一件事:过去一年,我往 Claude 里喂了多少业务数据、客户信息、甚至内部策略?这些东西全都躺在 Claude 的服务器上。
不是说 Claude 一定会拿去干嘛。但这种"我的核心资产存在别人家"的感觉,越想越不对劲。
所以我花了一个周末,折腾出了这么个东西:飞书里住着一个 AI 助手,跑的是完全本地的开源大模型,不花一分钱订阅费,数据不出本机。
开始之前先对个表:你需要一台 16GB 以上内存的电脑(Mac / Linux / Windows 都行)。如果内存不够,文中也有轻量版方案。整个过程大概 1-2 小时,但有几个坑我帮你提前标好了——跟着走能省掉大半天的排错。
先说说 Hermes Agent 是什么东西
Hermes Agent 是 Nous Research 开源的 AI Agent 项目(GitHub 4.5 万+ Star)。别被"Agent"吓到。你可以把它理解成一个住在你聊天软件里的私人 AI 助手,而且它有三个其他Agent做不到的事:
- 记得住你 — 跨会话保留上下文。不会每次都问"你是谁你要干嘛"
- 会自我进化 — 你教过它的东西会变成技能,越用越顺手
- 住在飞书里 — 像一个真人同事,随叫随到,不用切 App
项目地址:https://github.com/NousResearch/Hermes-Agent
接下来带你搞定三步:
- 装好本地大模型(Ollama + Gemma4,免费离线可用)
- 装好 Hermes Agent
- 把它塞进飞书
Part 1: 装 Ollama 和 Gemma4 模型
Gemma4 是 Google 开源的多模态大模型,支持文本和图片理解。通过 Ollama 在本地运行——不要 API Key,完全免费。
1.1 安装 Ollama
macOS — Homebrew 一行搞定:
brew install ollama
或者去 https://ollama.com 下载安装包,双击装。
Linux:
curl -fsSL https://ollama.com/install.sh | sh
Windows: 去 https://ollama.com 下载安装包。
1.2 启动 Ollama 服务
ollama serve
Mac 用安装包装的不用管——菜单栏会自动后台跑。
1.3 下载 Gemma4 模型
ollama pull gemma4:26b
26B 参数版本,下载约 15GB。需要 16GB 以上内存。
内存不够的方案:
ollama pull gemma4 # 默认小版本,8GB 内存也能跑
1.4 验证
ollama run gemma4:26b "你好,请介绍一下你自己"
正常回复就说明装好了。再验一下 API:
curl http://localhost:11434/v1/models
列表里有 gemma4:26b 就对了。
Part 2: 装 Hermes Agent
2.1 一条命令搞定
curl -fsSL https://raw.githubusercontent.com/NousResearch/hermes-agent/main/scripts/install.sh | bash
支持 macOS、Linux、WSL2、Android (Termux)。
Windows 用户先装 WSL:wsl --install,装完进 WSL 再跑上面的命令。
2.2 激活环境
source ~/.bashrc # 或 source ~/.zshrc
2.3 配置向导
hermes setup
交互式向导,按这个来:
| 步骤 | 说明 | 我的选择 |
|---|---|---|
| 大模型选择 | LLM 提供商 | 先跳过,下一步单独配 |
| 语音渠道 | TTS 语音合成 | 默认 Edge TTS |
| 终端后端 | 命令执行环境 | local |
| 任务迭代 | 单次任务最大步数 | 默认 90 |
| 显示模式 | 执行可见性 | all(强烈建议) |
| 上下文压缩 | 长对话压缩 | 默认 0.5 |
2.4 让 Hermes 用上 Gemma4
hermes model
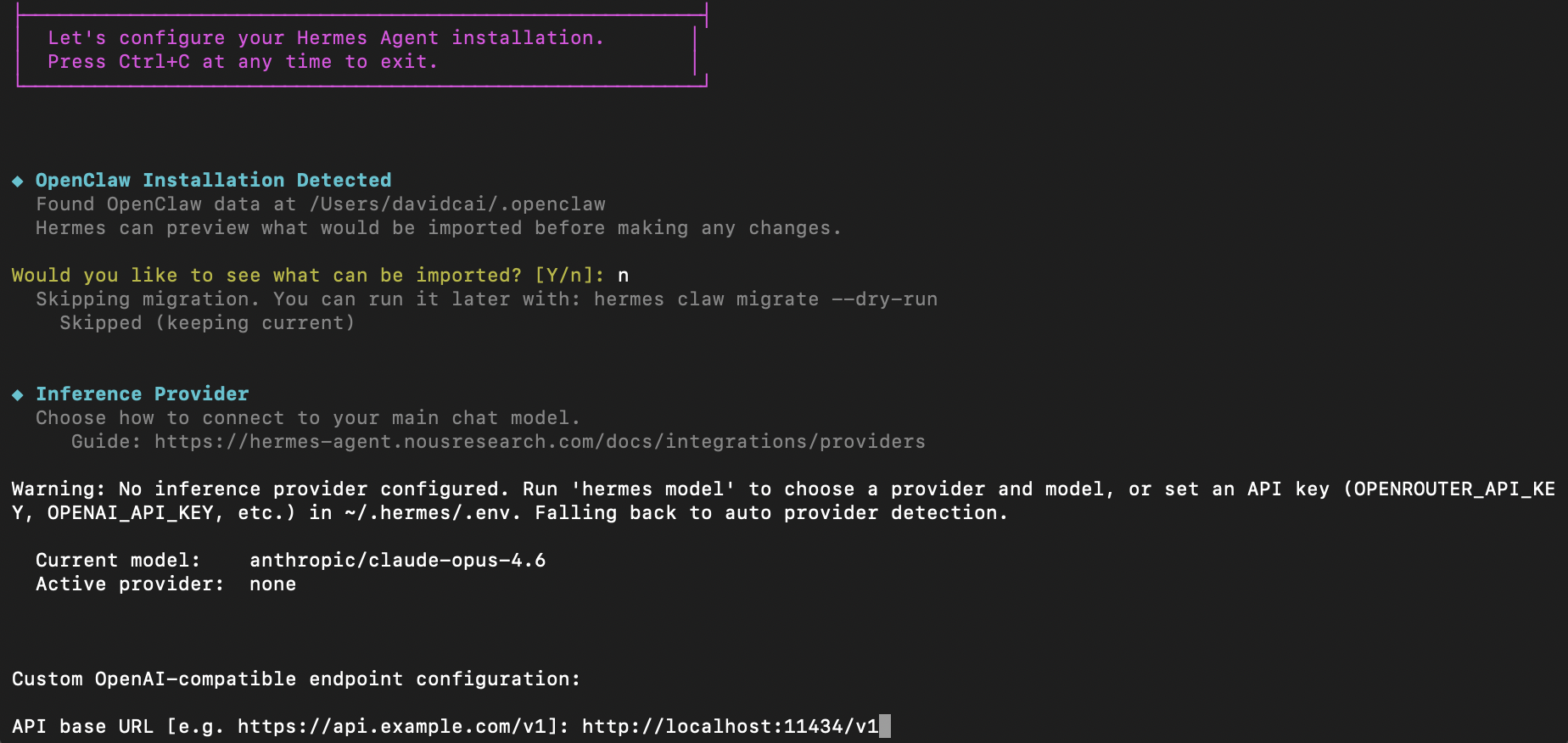
选 Custom / Local:
- Base URL:
http://localhost:11434/v1 - Model:
gemma4:26b
2.5 测试
hermes
说句"你好"——如果 Gemma4 回话了,恭喜,本地 AI 助手已经跑起来了。
Part 3: 接入飞书——最容易翻车的一步
说真的,前两步我半天就搞定了。但飞书这步,我折腾到凌晨两点。
罪魁祸首就是 Python 虚拟环境。
3.1 创建飞书应用
- 打开 飞书开放平台
- 创建企业自建应用,起个名("Hermes 助手")
- 记下 App ID(
cli_xxxxxxxxxx)和 App Secret - 左侧 → 添加应用能力 → 加机器人
- 事件订阅 → 选 WebSocket 长连接(不用公网 IP)
- 发布应用(需管理员审批)
3.2 安装飞书 SDK——整篇最大的坑
⚠️ 血泪教训
你的第一反应肯定是
pip install lark-oapi。别。
这样十有八九装进了系统 Python。但 Hermes 用的是自己带的虚拟环境,跟你的系统 Python 完全隔离。结果就是报错
lark-oapi not installed,你反复确认 App ID 和 Secret 都没问题,抓狂半天——其实就是装错了地方。这个坑我踩了整整两小时。
正确姿势——必须装到 Hermes 自己的 venv 里:
~/.hermes/hermes-agent/venv/bin/python -m ensurepip
~/.hermes/hermes-agent/venv/bin/python -m pip install lark-oapi
验证:
~/.hermes/hermes-agent/venv/bin/python -c "import lark_oapi; print('OK')"
3.3 配置飞书网关
hermes gateway setup
选 Feishu,填入 App ID 和 App Secret,连接方式选 WebSocket。
想让所有人都能跟机器人聊,在 ~/.hermes/.env 加一行:
GATEWAY_ALLOW_ALL_USERS=true
3.4 启动
hermes gateway
看到下面这个就说明成了:
⚕ Hermes Gateway Starting...
Messaging platforms + cron scheduler
Press Ctrl+C to stop
3.5 配对
- 在飞书找到机器人,发条消息
- 终端会显示配对码,输入完成
- 发
/sethome设为主频道
常见问题
lark-oapi not installed / No adapter available for feishu
→ 装错了 Python 环境。回 3.2,用 Hermes 自带的 venv 重装。
飞书发消息没回复,但 gateway 还在?
→ WebSocket 断了,Ctrl+C 重启 hermes gateway。
Ollama 下载慢?
→ 挂代理:export HTTPS_PROXY=http://127.0.0.1:7890 再拉。
模型回复慢?
→ 26B 吃配置,Mac 建议 32GB 以上内存。不够就 hermes model 切小模型,或用 OpenRouter 等云端服务。
写在最后:为什么我觉得这件事值得折腾
折腾完这一套,你得到的不只是一个免费 AI 助手。
你得到的是数据主权。
想想看:你的工作笔记、客户资料、商业策略,全部只在你自己的电脑上处理。不经过任何第三方服务器,不受任何公司的隐私政策约束。在 AI 渗透到工作每个角落的今天,这件事的价值只会越来越大。
而且这套方案的成本是——零。
Hermes Agent 开源免费。Gemma4 开源免费。Ollama 开源免费。你唯一需要付出的就是一个周末的折腾时间。
说个会引战的观点: 我觉得未来两年内,"AI 数据放在谁那里"会变成跟"钱存在哪个银行"一样重要的问题。你是选择继续每月付费、把数据交给大厂,还是花一个周末把 AI 搬回自己手里?
评论区站个队。顺便也欢迎分享你的使用场景——我目前主要用来做信息整理和会议纪要,但总觉得还没发挥出它的全部潜力。
觉得有用就收藏一下,免得哪天想装的时候找不到。